accounts-app
simple account app
react/一个功能简单的小账本,记录现金的流入流出/可以做假账(随时编辑历史记录)
GitHub源地址:https://github.com/0rainge/accounts-app
0. 项目总结
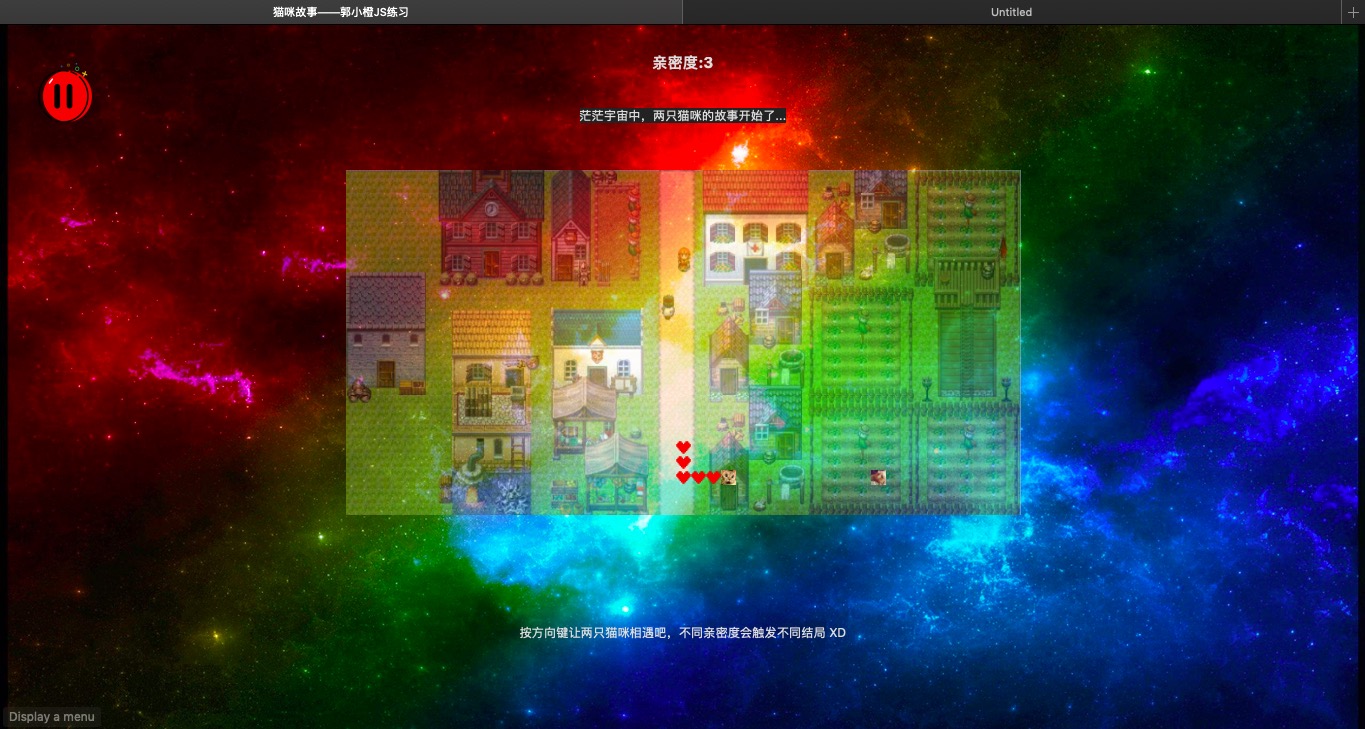
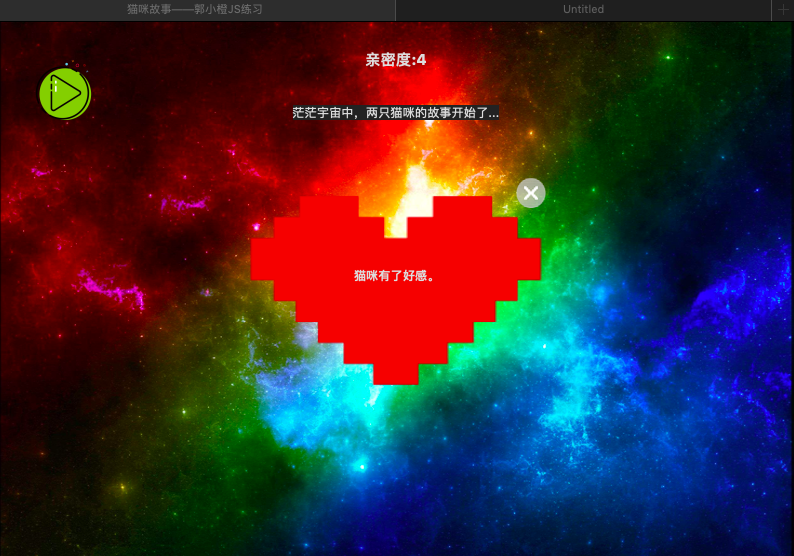
0-1. 展示
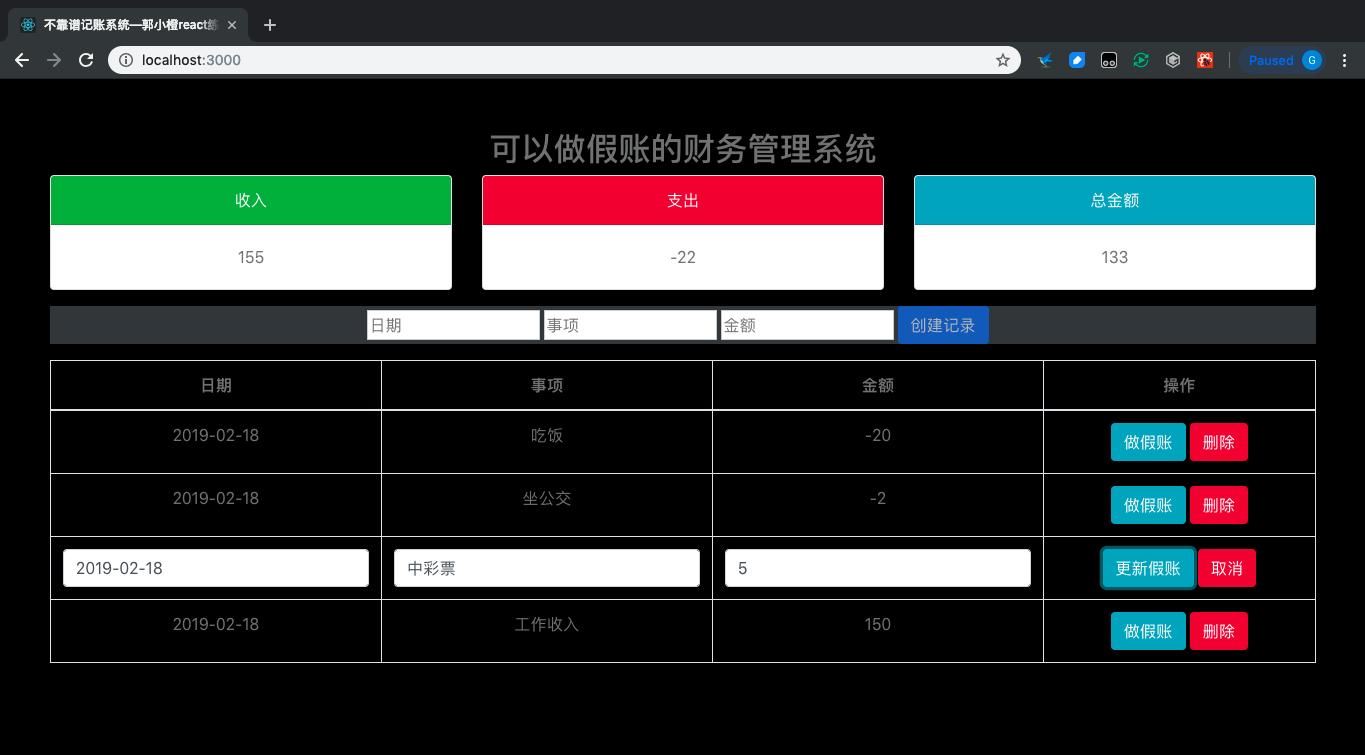
0-2. 功能点
- 展示记录(设置表格,展示每条记录)
- 创建记录(设置表单,输入记录:时间,事项,收支金额)
- 计算并展示总金额(设置数据展示卡片,计算收入、支出、总金额并展示)
- 更新/删除记录(在表单中实现数据的更新和删除)
Read More
也可以看成一个ToDoList
a To-Do-List using jQuery, nodejs, Express, mongoDB
实现一个flag清单,添加或删除flag
前端使用模版引擎EJS,引用jQuery库,后端使用nodejs,采用express框架,数据储存在mongoDB上
GitHub源地址:https://github.com/0rainge/myToDoList
界面展示:
前端:

后端:

Read More
定义:
压缩神经网络参数——轻量化网络
SqueezeNet是一个小型化的网络模型结构,在保证不降低检测精度的同时,用了比AlexNet少50倍的参数。
同时采用了deep compression技术,对squeezenet进行了压缩,将原始AlexNet模型压缩至原来的1/500(模型文件< 0.5MB,原始AlexNet模型约为200MB,同时增大了计算量。
措施:
- 将一部分3x3的filter(卷集核)替换成1x1的filter;
本文替换3x3的卷积kernel为1x1的卷积kernel可以让参数缩小9X。但是为了不影响识别精度,并不是全部替换,而是一部分用3x3,一部分用1x1。
- 减少输入的channels(3x3卷积核的input feature map数量,输入通道数);
如果是conv1-conv2这样的直连,那么实际上是没有办法减少conv2的input feature map数量的。因此把一层conv分解为两层,封装为一个Fire Module。使用squeeze layers来实现。
- 在整个网络后期才进行下采样,使得卷积层有比较大的activation maps;
分辨率越大的特征图(延迟降采样)可以带来更高的分类精度,因为分辨率越大的输入能够提供的信息就越多。将欠采样操作延后,可以给卷积层提供更大的激活图:更大的激活图保留了更多的信息,可以提供更高的分类准确率。
其中:措施1、2可降低参数数量。措施3用来大化网络精度。
fire module:
一个类似inception的网络单元结构。SqueezeNet的网络结构由若干个 fire module 组成。
将原来一层conv层变成两层:squeeze卷集层(有1x1卷集核)+expand卷集层(1x1和3x3卷积核)。
- 策略1:squeeze层用1x1的卷集filter。squeeze层借鉴了inception的思想,利用1x1卷积核来降低输入到expand层中3x3卷积核的输入通道数channels。
- 策略2: 定义squeeze层中1x1卷积核的数量是s1x1,expand层中1x1卷积核的数量是e1x1, 3x3卷积核的数量是e3x3。令s1x1 < e1x1+ e3x3从而保证输入到3x3的输入通道数减小,这样squeeze layer可以限制输入通道数量。
激活函数:为了保证1x1卷积核和3x3卷积核具有相同大小的输出,3x3卷积核采用1像素的zero-padding和步长 squeeze层和expand层均采用RELU作为激活函数 。
Fire module输入的feature map为HWM的,输出的feature map为HM(e1+e3),可以看到feature map的分辨率是不变的,变的仅是维数,也就是通道数,这一点和VGG的思想一致。
首先,HWM的feature map经过Squeeze层,得到S1个feature map,这里的S1均是小于M的,以达到“压缩”的目的。
其次,HWS1的特征图输入到Expand层,分别经过11卷积层和33卷积层进行卷积,再将结果进行concat,得到Fire module的输出,为 HM(e1+e3)的feature map。
fire模块有三个可调参数:S1,e1,e3,分别代表卷积核的个数,同时也表示对应输出feature map的维数,在本文提出的SqueezeNet结构中,e1=e3=4s1
模型:
SqueezeNet以卷积层(conv1)开始,接着使用8个Fire modules (fire2-9),最后以卷积层(conv10)结束。每个fire module中的filter数量逐渐增加,并且在conv1, fire4, fire8, 和 conv10这几层之后使用步长为2的max-pooling,即将池化层放在相对靠后的位置,这使用了以上的策略(3)。
最后是一个conv10,在fire9后采用50%的dropout 由于全连接层的参数数量巨大,因此借鉴NIN的思想,去除了全连接层FC而改用global average pooling。
减少参数的优点:
1、实现更高效的分布式训练;
服务器间的通信是分布式CNN训练的重要限制因素。对于分布式 数据并行 训练方式,通信需求和模型参数数量正相关。小模型对通信需求更低。
2、训练出轻量级的模型,减小下载模型到客户端的额外开销 ;
比如在自动驾驶中,经常需要更新客户端模型。更小的模型可以减少通信的额外开销,使得更新更加容易。
3、在FPGA和嵌入式硬件上的部署实现;
GitHub项目:
SqueezeNet https://github.com/DeepScale/SqueezeNet 1.4k star
SqueezeNet-Deep-Compression: https://github.com/songhan/SqueezeNet-Deep-Compression 314 star https://arxiv.org/abs/1602.07360
SqueezeNet-Generator: https://github.com/songhan/SqueezeNet-Generator
SqueezeNet-DSD-Training: https://github.com/songhan/SqueezeNet-DSD-Training
SqueezeNet-Residual: https://github.com/songhan/SqueezeNet-Residual
https://github.com/vonclites/squeezenet 52 star 有原论文 https://arxiv.org/abs/1602.07360
https://github.com/rcmalli/keras-squeezenet 251 star Keras实现 squeezenet
https://github.com/DT42/squeezenet_demo 175 star
相关论文:
https://arxiv.org/pdf/1602.07360v3.pdf squeezenet用了比AlexNet少50倍的参数,达到了AlexNet相同的精度
https://arxiv.org/pdf/1506.02626v3.pdf Learning both Weights and Connections for Efficient Neural Network (NIPS’15)
https://arxiv.org/pdf/1510.00149v5.pdf 深度压缩,用剪枝来压缩深度神经网络,训练量化和 Huffman 编码
https://arxiv.org/pdf/1602.01528v1.pdf 压缩神经网络的Efficient Inference Engine
总结:
squeezenet采用“多层小卷积核”策略,通过增加计算量换来更少的参数,把参数读取的代价转移到计算量上。计算耗时还是要远远小于数据存取耗时的,是“多层小卷积核”策略成功的根源。
其他:
mobilenet和,squeezenet都是alexnet参数量1/50,mobilenet速度比alexnet快10倍,squeezenet提升3%
Read More
复现activitynet2016未剪辑视频分类冠军算法模型:
代码链接:https://github.com/yjxiong/anet2016-cuhk
系统:ubuntu
装上unzip和cmake
复现activitynet2016未剪辑视频分类冠军算法模型:https://github.com/yjxiong/anet2016-cuhk
主要通过脚本安装https://github.com/yjxiong/anet2016-cuhk/blob/master/build_all.sh
环境准备如下:
- 安装anaconda
- 安装caffe
- 安装tensorflow
- 安装opencv
脚本有一些地方运行不了,整理的之后步骤如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
|
#!/usr/bin/env bash
# TODO: add compilation steps
# update the submodules: Caffe and Dense Flow
git submodule update --remote
# install Caffe dependencies
sudo apt-get -qq install libprotobuf-dev libleveldb-dev libsnappy-dev libhdf5-serial-dev protobuf-compiler libatlas-base-dev
不对!!!!!!!!!!sudo apt-get -qq install --no-install-recommends libboost1.55-all-dev
改成sudo apt-get -qq install --no-install-recommends libboost-all-dev
sudo apt-get -qq install libgflags-dev libgoogle-glog-dev liblmdb-dev
# install Dense_Flow dependencies
sudo apt-get -qq install libzip-dev
# install common dependencies: OpenCV
# adpated from OpenCV.sh
version="2.4.13"
echo "Building OpenCV" $version
mkdir 3rd-party/
cd 3rd-party/
echo "Installing Dependenices"
不对!!!!!!!!!sudo apt-get -qq install libopencv-dev build-essential checkinstall cmake pkg-config yasm libjpeg-dev libjasper-dev libavcodec-dev libavformat-dev libswscale-dev libdc1394-22-dev libxine-dev libgstreamer0.10-dev libgstreamer-plugins-base0.10-dev libv4l-dev python-dev python-numpy libtbb-dev libqt4-dev libgtk2.0-dev libfaac-dev libmp3lame-dev libopencore-amrnb-dev libopencore-amrwb-dev libtheora-dev libvorbis-dev libxvidcore-dev x264 v4l-utils
改成sudo apt-get -qq install libopencv-dev build-essential checkinstall cmake pkg-config yasm libjpeg-dev libjasper-dev libavcodec-dev libavformat-dev libswscale-dev libdc1394-22-dev libxine2-dev libgstreamer0.10-dev libgstreamer-plugins-base0.10-dev libv4l-dev python-dev python-numpy libtbb-dev libqt4-dev libgtk2.0-dev libfaac-dev libmp3lame-dev libopencore-amrnb-dev libopencore-amrwb-dev libtheora-dev libvorbis-dev libxvidcore-dev x264 v4l-utils
echo "Downloading OpenCV" $version
echo "Installing OpenCV" $version
unzip OpenCV-$version.zip
cd opencv-$version
mkdir build
cd build
cmake -D CMAKE_BUILD_TYPE=RELEASE -D WITH_TBB=ON -D WITH_V4L=ON -D WITH_QT=ON -D WITH_OPENGL=ON ..
!!!!!!!!!!
在这里Makefile.config加入:
LINKFLAGS := -Wl,-rpath,/root/anaconda3/lib
!!!!!!!!!!
??????????cmake -D CMAKE_BUILD_TYPE=RELEASE -D CMAKE_INSTALL_PREFIX=/usr/local -D WITH_TBB=ON -D BUILD_NEW_PYTHON_SUPPORT=ON -D WITH_V4L=ON -D INSTALL_C_EXAMPLES=ON -D INSTALL_PYTHON_EXAMPLES=ON -D BUILD_EXAMPLES=ON -D BUILD_TIFF=ON -D WITH_OPENGL=ON..
cmake -D CMAKE_BUILD_TYPE=RELEASE -D WITH_TBB=ON -D WITH_V4L=ON -D WITH_QT=ON -D WITH_OPENGL=ON -D BUILD_TIFF=ON ..
cp lib/cv2.so ../../../
echo "OpenCV" $version "built"
# build dense_flow
cd ../../../
echo "Building Dense Flow"
cd lib/dense_flow
mkdir build
cd build
OpenCV_DIR=../../../3rd-party/opencv-$version/build/ cmake .. -DCUDA_USE_STATIC_CUDA_RUNTIME=OFF
make -j
!!!!!!!!需要下载
echo "Dense Flow built"
https://github.com/jaejunlee0538/openfabmap/issues/3
# build caffe
echo "Building Caffe"
cd ../../caffe-action
mkdir build
cd build
OpenCV_DIR=../../../3rd-party/opencv-$version/build/ cmake .. -DCUDA_USE_STATIC_CUDA_RUNTIME=OFF
!!!!!!!!!!!!!!!改成
OpenCV_DIR=../../../3rd-party/opencv-$version/build/ cmake .. -DCUDA_USE_STATIC_CUDA_RUNTIME=OFF -D BUILD_TIFF=ON
然后如果你装了anaconda包的话,删除anaconda/lib/下面的 libm https://blog.csdn.net/ccemmawatson/article/details/42004105
sudo rm -rf libm*
make -j32
echo "Caffe Built"
cd ../../../
# install python packages
pip install -r py_requirements.txt
# setup for web demo
mkdir tmp
# copy website files to the folder
wget -O 3rd-party/bootstrap-fileinput.zip https://github.com/kartik-v/bootstrap-fileinput/zipball/master
cd 3rd-party
unzip bootstrap-fileinput.zip
mv kartik-v-bootstrap-* Bootstrap-fileinput
!!!!!!!!!!!cannot move 'kartik-v-bootstrap-fileinput-61c9523' to 'Bootstrap-fileinput/kartik-v-bootstrap-fileinput-61c9523': Directory not empty
cp -r Bootstrap-fileinput/js ../static/js
cp Bootstrap-fileinput/css/* ../static/css/
export ANET_HOME=/root/anet2016-cuhk
|
Read More
作者
Feng Mao
思路
提取CNN和C3D特征作为帧特征,使用average pooling 和 LSTM 将帧特征聚集为视频特征,使用MoE进行分类
CNN_C3D_averagePooling_LSTM_MoEcd
特征提取
CNN:使用数据集ImageNet 21k 训练模型inception-v1 。在分类层POOL5/7X7YS1,选择分类层之前的那一个hidden层作为帧级特征第一部分。
C3D:使用PCA降维
特征聚合
无监督 average pooling
有监督 aggregation LSTM
分类
MoE(Mixture of experts) ,结合不同特征和不同聚合模型:
- CNN + average pooling
- CNN + LSTM
- C3D + average pooling
- C3D + LSTM
需要训练的参数是CNN and C3D 的LSTM参数和 MoE parameters
Read More